Hi,
I need help troubleshooting a rather weird error. I have setup a (single instance) Azure VM to run Neo4j following the official documentation to feed data to an Azure Databricks cluster running Spark. I connected to the Neo4j VM via HTTP on port 7474 to populate it with some data. For the Databricks cluster, I installed the connector and followed this documentation, basically just setting the connection address and login credentials as Spark parameters.
When I run a sample query via the spark connector on the Databricks cluster, I can successfully establish a connection - however, it only returns empty data:
%scala
import org.neo4j.spark._
val neo = Neo4j(sc)
# => neo: org.neo4j.spark.Neo4j = org.neo4j.spark.Neo4j@7c444d23
%scala
val rdd = neo.cypher("MATCH (n:Person) RETURN id(n) as id ").loadRowRdd
rdd.count
# => rdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = Neo4jRDD partitions Partitions(1,9223372036854775807,9223372036854775807,None) MATCH (n:Person) RETURN id(n) as id using Map()
# => res1: Long = 0
the same happens for .loadDataFrame, .loadGraphFrame etc:
# => java.lang.RuntimeException: Cannot infer schema-types from empty result, please use loadDataFrame(schema: (String,String)*)
I can confirm that the query should in fact not return an empty DF by connecting to the remote VM from my local Neo4j Desktop and running it there:
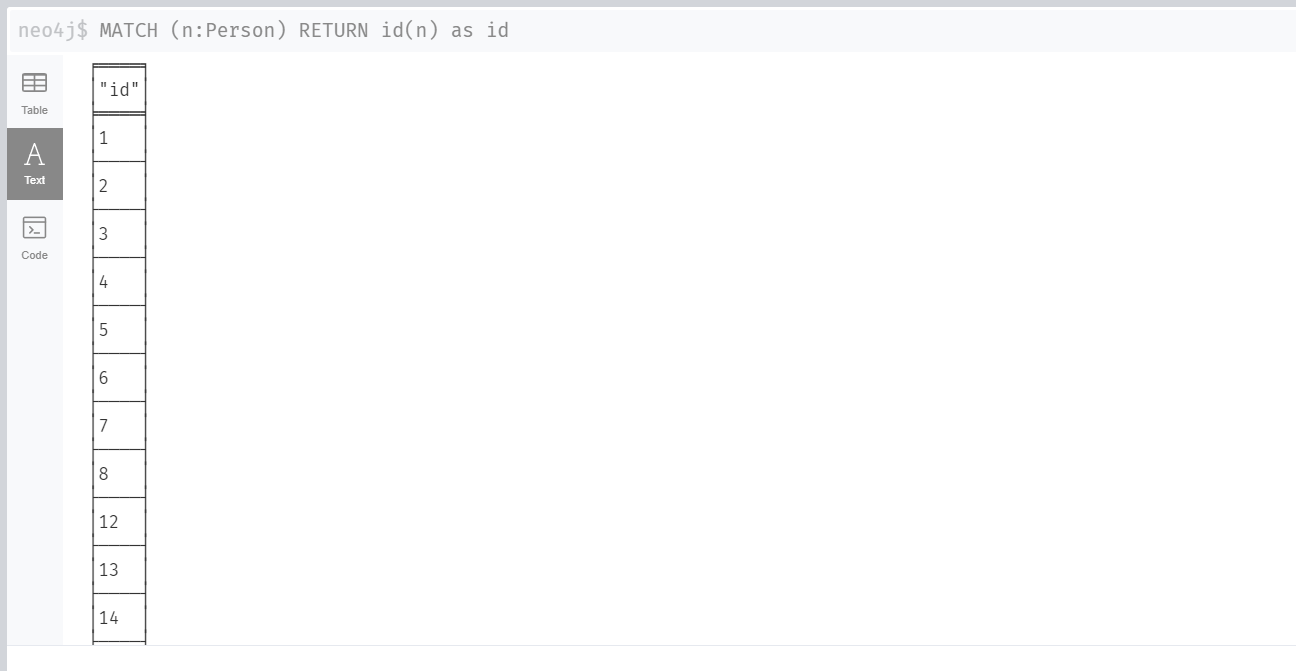
Where is my mistake here? Thanks in advance!
(Logs and specs, see below)