Hello all,
I am using this query to extract products similar to a product in a certain category within a price range and it is taking a lot of time.
**match(p1:Product) ** with p1 limit 5000 match(p1)<-[:HasProduct]-(c:Category)-[:HasProduct]->(p:Product) where tofloat(p.Price)>0.5tofloat(p1.Price) and tofloat(p.Price)<2tofloat(p1.Price) with p1, collect(p)[..3] as products return p1.ProductId, [product in products | product.ProductId] as pid
There are 87000 product nodes and 219 category nodes. With a limit 0f 5000, it is taking around 8 minutes to return.
Hello there,
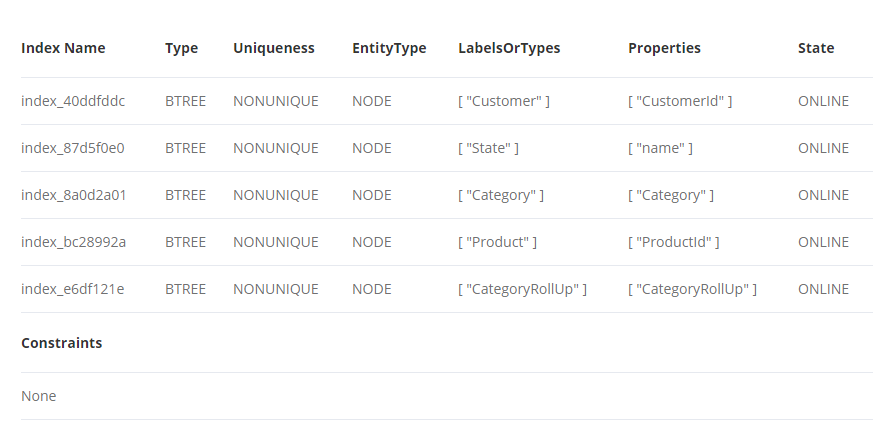
I haven't added any constraints on my nodes (Probably because I am not very sure about them). Maybe you can help me with the same. I have already showed you my created indexes.
Here is my query for the node and relationship creation with all the labels and their properties.
:auto using periodic commit 5000 load csv with headers from "file:///data.csv" as line merge (s:State{name:line.State}) merge (p:Product{ProductId:line.ProductId,Price:tofloat(line.ProductPrice),ProductName:line.ProductName}) merge (c:Category{Category:line.Category}) merge (cr:CategoryRollUp{CategoryRollUp:line.CategoryRollUp}) merge (cu:Customer{CustomerId:line.CustomerId,Grouping:line.NewGrouping}) merge (cu)-[:InteractsWith{Date:date(line.TransactionDate),Month:line.Month,EventScore:tofloat(line.EventScore),Event:line.Event,Quantity:toInteger(line.QtySold)}]->(p) merge (s)-[:HasUser]->(cu) merge (c)-[:HasProduct]->(p) merge (cr)-[:HasCategory]->(c)
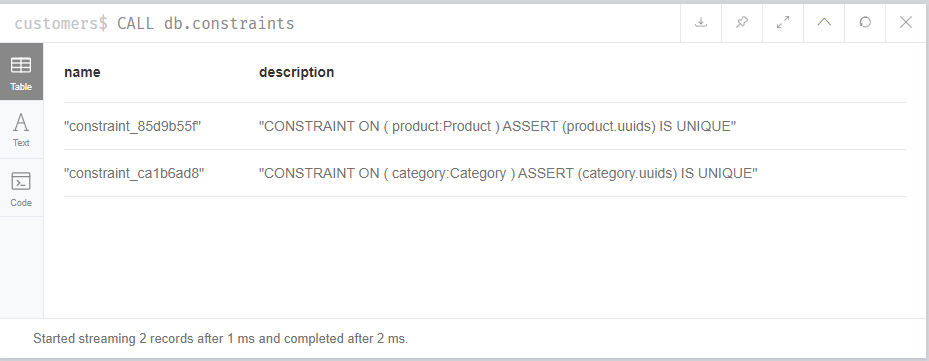
I have tried creating a constraint on the Price property of the Product Label but certainlt that is not unique so it showed me an error.
Can you guide me in creating contraints for the same?
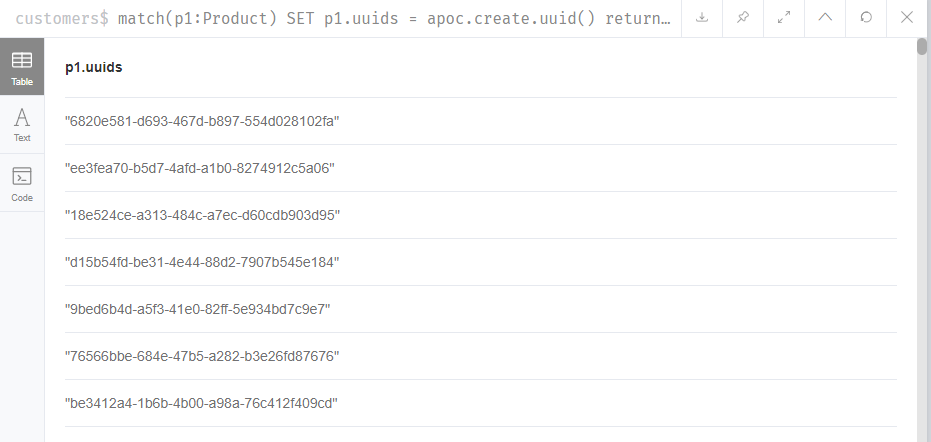
Hii there, I have created a unique id constraint by following the link you shared after adding a uuid property to the Product node. The code and screen grab for the same is here:
match(p1:Product) SET p1.uuids = apoc.create.uuid() return p1.uuids
I think it's because of your Cypher request, it's doing several Merge at the same time. On my projects, I have at least 2 requests:
one to merge nodes from a batch
one to merge relations from a batch
and I call them several times and I can create thousand of nodes and relations in a few seconds:)
Do you currently have your data in the same CSV file? So you use a single line to get everything you need, how many times does it take to create all the nodes and relationships?
I have no issue with the node and relationship creation query with that query I am able to make around 100000 nodes and 1.7 million relationships in 9 minutes but I am having issue with the following read type query:
match(p1:Product) with p1 limit 5000 match(p1)<-[:HasProduct]-(c:Category)-[:HasProduct]->(p:Product) where tofloat(p.Price)>0.5 tofloat(p1.Price) and tofloat(p.Price)<2 tofloat(p1.Price) with p1, collect(p)[..3] as products return p1.ProductId, [product in products | product.ProductId] as pid
With only 5000 products it took around 15 minutes to return and there are 87000 unique products
MATCH (p1:Product)<-[:HasProduct]-(c:Category)-[:HasProduct]->(p:Product)
WHERE tofloat(p.Price) > 0.5 * tofloat(p1.Price)
AND tofloat(p.Price) < 2 * tofloat(p1.Price)
WITH p1, collect(p)[..3] AS products
RETURN p1.ProductId, [product in products | product.ProductId] AS pid
I have already set the initial and maximum heap size to 20 and 24GB respectively but still it is not running the query. I have a 7 node cluster on the server each with similar specifications.
I didn't use it at the moment, did you try to create a simple local database to test without Causal Clustering if the same query was taking the same time or not?