Hi,
I have a string of 1000 nodes connected together by the same relationship and there are no other relationships going in or out (ie one NEXT relationship in and one out). I was surprised that when I went to query to get the whole string of nodes, that it hit the database over 132 000 times and took a very long time to process. Finding the first node was done via an index and the structure of the query is:
MATCH p=(n:Document {name: "mydocument"})-[:NEXT*]->(:DocumentSection) RETURN p
So I'm doing something wrong here but I thought that finding the first node was meant to be the slowest part (again I indexed this) and then the relationships were pointers that just had to be followed by the DB engine?
Thanks in advance.
That should be the case. Can you PROFILE the query in the browser and provide the profile plan?
Hi Andrew,
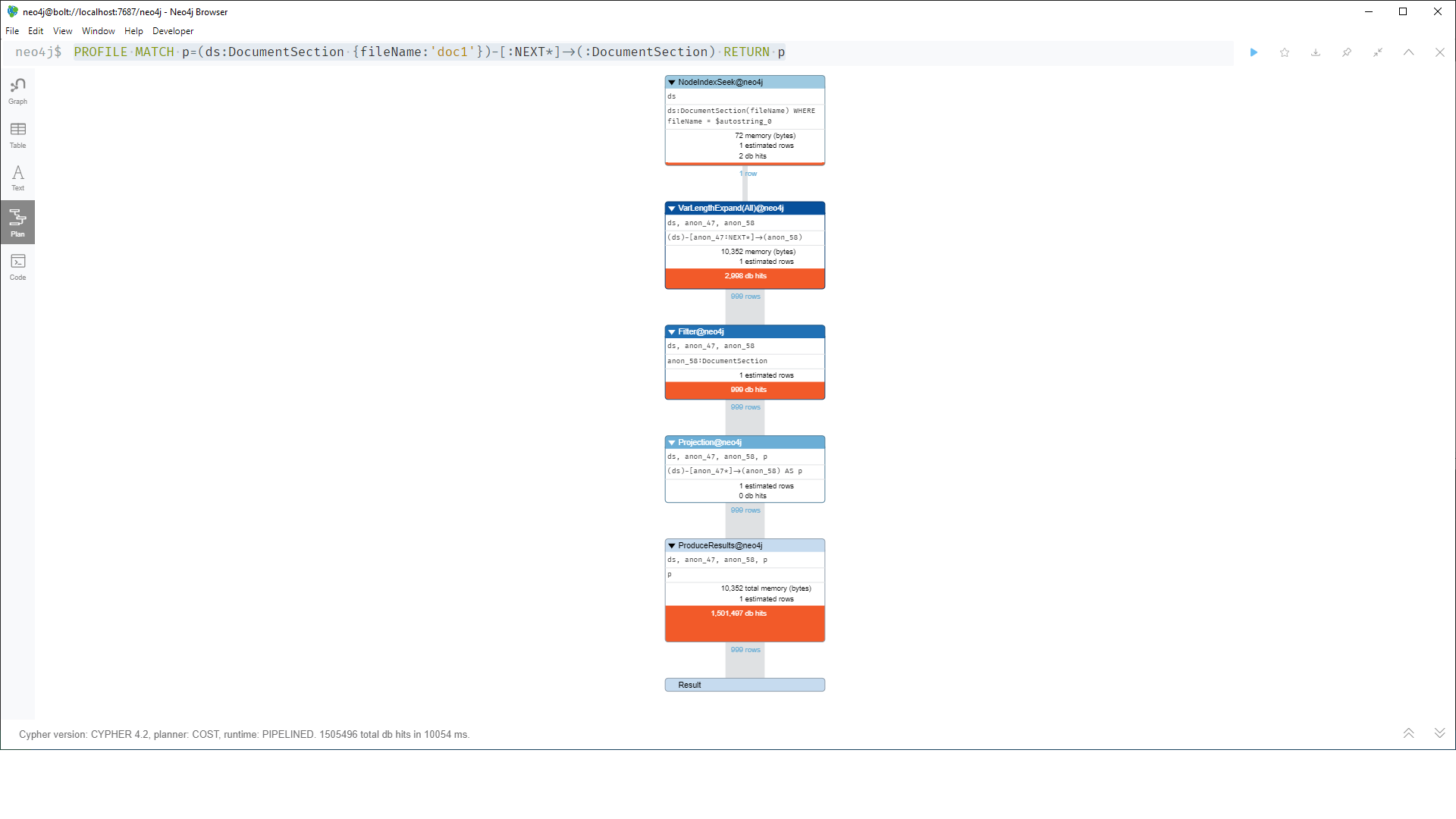
Attached is the profile plan. When I recreated the graph for this response, it used 1.5m database hits.
To create the graph:
FOREACH(r in range(1,1000) | CREATE (n:DocumentSection {fileName:'doc'+r, sequence:r}));
MATCH (ds:DocumentSection) WITH ds ORDER BY ds.sequence ASC WITH collect(ds) as dsCollect CALL apoc.nodes.link(dsCollect, 'NEXT') RETURN count(dsCollect);
And the query I ran:
PROFILE MATCH p=(ds:DocumentSection {fileName:'doc1'})-[:NEXT*]->(:DocumentSection) RETURN p;
Thanks.
So for a single linked list of those 1000 nodes, a query like yours may be expensive:
PROFILE MATCH p=(ds:DocumentSection {fileName:'doc1'})-[:NEXT*]->(:DocumentSection) RETURN p;
While you are only getting 999 rows of results, each result is a subpath of the next result. So the very last result has a path length of 999 (999 relationships connecting 1000 nodes) and the row before that is the subpath of that minus 1 node, and the path before that one has 998 nodes, etc. So the root node will be accessed 999 times (once per path it occurs on), the second node will be accessed 998 times, the third will be accessed 997 times, etc.
If you wanted a single path instead of all subpaths, then you would need to specify the condition for which there is no :NEXT relationship (provided that makes sense for your dataset):
PROFILE MATCH p=(ds:DocumentSection {fileName:'doc1'})-[:NEXT*]->(end:DocumentSection)
WHERE NOT (end)-[:NEXT]->()
RETURN p;
That one would only return a path to a leaf node that doesn't have a :NEXT relationship, so each node would only appear once (and be accessed once) for the single path that includes it.
Alternately, if you are only interested in the connected :DocumentSection nodes and don't need to deal with the paths or relationships, then this approach should work fine:
PROFILE
MATCH (ds:DocumentSection {fileName:'doc1'})-[:NEXT*]->(end:DocumentSection)
RETURN end
That will result in only a single node per row, and won't require multiple accesses per node in the path. If it needs to include the starting node too, then you can use *0.. to include it.
2 Likes
A ha! Thanks a lot for the explanation Andrew, that makes sense and has helped a lot with my understanding of what the query is doing under the hood.