My current code below runs for a long time for 100001 alias nodes:
CALL apoc.periodic.iterate("MATCH (a:alias) RETURN a",
"Match
path=((a) -- (c1:citation) -[p1]-> (t:BIOTERM) <-[p2]- (c2:citation) -- (b:alias))
WHERE id(a) < id(b) AND id(c1) <> id(c2)
With a, b, p1, p2, 2 as precision
WITH a, b, p1, p2, 10^precision as factor
Create (a)-[e:through_topic]->(b)
Set e.weight= round(factor* (1/(2+p1.weight+p2.weight))) / factor", {batchSize:1000}) YIELD batches, total, errorMessages
When I ran for a single alias
Match
path=((a:alias {name: 293} ) -- (c1:citation) -[p1]-> (t:BIOTERM) <-[p2]- (c2:citation) -- (b:alias))
WHERE id(a) < id(b) AND id(c1) <> id(c2)
With a, b, p1, p2, 2 as precision
WITH a, b, p1, p2, 10^precision as factor
Create (a)-[e:through_topic]->(b)
Set e.weight= round(factor* (1/(2+p1.weight+p2.weight))) / factor
completed in 1 or 2 ms. Should I try to optimize my code or play more with the batchsize of the apoc.periodic.iterate or both? I had no luck decreasing the batchsize.
I ran EXPLAIN and PROFILE with
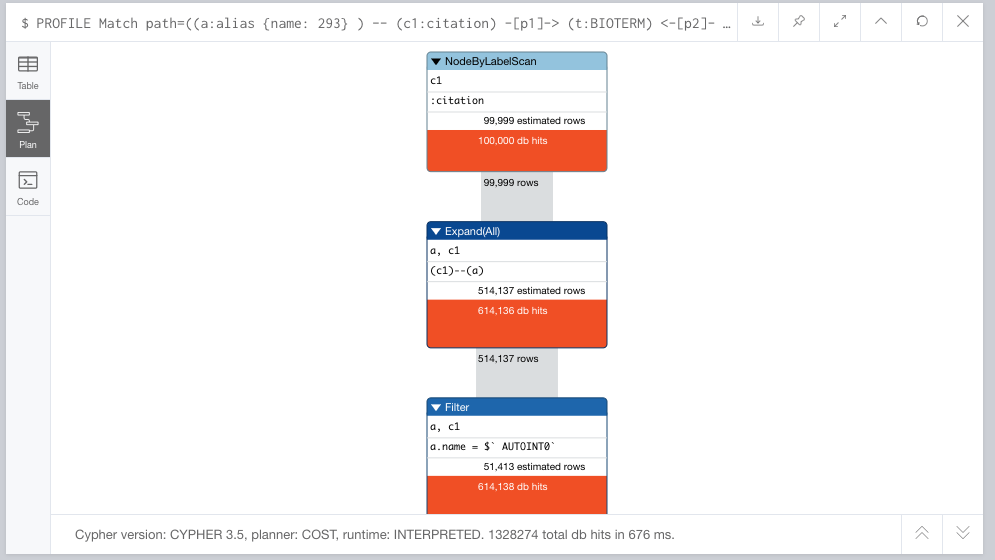
Thanks,
Lavanya