I have, what i think is a relatively straightforward cypher query that is unexpectedly slow:
MATCH (potential_user:GraphUser)
WITH potential_user, distance(point({srid:4326, x:-140.0312186, y:39.33233141}), potential_user.location) as distance
WHERE potential_user.is_banned=false AND potential_user.is_paused=false AND potential_user.is_invisible=false AND potential_user.profile_complete=true
AND
distance < 100000
RETURN count(potential_user)
There are only about 120K GraphUser nodes. Here is the PROFILE:
I think what you want to do is force Cypher to do a cheap conditional filtering before doing the location filtering. If you look at the PROFILE, you see the big fat red sections occurring early which is what is slowing your query down. I'm sure if you do the profile of what's within the CALL subquery statement below, the big fat red sections will shrink.
You want to do something like this.... (I'm still at the intermediate level, so this almost certainly not exactly right. Cypher is still a bit of a mystery to me. If/when you figure it out, I'll fix my answer.)
MATCH (potential_user:GraphUser)
CALL { // filter out as many potential_users as possibly as cheaply as possible
WHERE potential_user.is_banned=false AND
potential_user.is_paused=false AND
potential_user.is_invisible=false AND
potential_user.profile_complete=true
RETURN potential_user
} // this part I am not so sure about:
WITH potential_user, distance(point({srid:4326, x:-140.0312186, y:39.33233141}), potential_user.location) AS distance
MATCH(potential_user) WHERE distance < 100000
RETURN count(potential_user)
Don't take it wrong, I think I can help a bit, but your query is a mess.
The reason why it's difficult for Neo4j to compute it properly and quickly is roughly that.
SQL has only 2 dimensions to care about, that's why it's faster on SQL.
Neo4j has a multidimensional Graph domain to care about + a projected data domain.
I'm good with the Cypher language but not quite a query tuning expert yet.
But, according to what I can read on your query profile, thank you for having it, Neo4j doesn't even use your index right now.
The first thing I would try it's to put your WHERE clause after the first match clause, at least the property you can, it should improve a lot but the query tuning won't be complete after that.
as previously stated per above the first block from the PROFILE is a NodeScanByLabel and thus it not using the index.
And although you have not indicated what version of Neo4j, I am able to reproduce your behavior under 4.2.2 and also have a workaround so as to have the index used. For example my workaround code is
:use system
drop database graphUser;
create database graphUser;
:use graphUser;
// create single index on 4 properties, i.e. the properties in the where clause
create index index01 for (n:GraphUser) on (n.is_banned, n.is_paused, n.is_invisible, n.profile_complete);
call db.indexes();
// create some dummy data
foreach ( x in range (1,100) | create (n:GraphUser {id:x, profile_complete: true, potential_user: false, is_banned: false, is_paused: true}));
foreach ( x in range (101,300) | create (n:GraphUser {id:x, profile_complete: false, potential_user: false, is_banned: true, is_paused: true}));
foreach ( x in range (301,10000) | create (n:GraphUser {id:x, profile_complete: false, potential_user: true, is_banned: true, is_paused: false}));
profile MATCH (potential_user:GraphUser)
WHERE potential_user.is_banned=false AND potential_user.is_paused=false AND potential_user.is_invisible=false AND potential_user.profile_complete=true
WITH potential_user, distance(point({srid:4326, x:-140.0312186, y:39.33233141}), potential_user.location) as distance
where distance < 100000
RETURN count(potential_user);
the main difference between your original post and my workaround is in the MATCH statement I have moved the WHERE clause up. With my example code the PROFILE reports its first block as a NodeIndexSeek
Thank you guys, this very helpful! I didn't know you could move around WITH and WHERE like that.
Indeed, the modified query is now using the index. Still, it's not performing well, averaging about 180ms.
PROFILE MATCH (potential_user:GraphUser)
WHERE (potential_user.is_banned=false AND potential_user.is_paused=false AND potential_user.is_invisible=false AND potential_user.profile_complete=true)
WITH potential_user, distance(point({srid:4326, x:-140.0312186, y:39.33233141}), potential_user.location) as distance
WHERE distance < 100000
RETURN count(potential_user);
The big fat RED sections shows the slow sections. For the DISTANCE query, it is run on all 2.6M nodes.
Did you try my subquery I suggested above? I think that would help because the DISTANCE calculation would be only done on the 91K results from the boolean sub-query instead of all 2.6M nodes in the DB. I'm not sure if the query planner could be smarter, but it's being sub-optimal.
In theory, you could create a bounding box that includes a box around the geo-location results of the first boolean part of the query. Then somehow limit the distance calculation to only those points that fall within the bound box. But I've never played with Neo4J GeoLocations, so I don't know if that's possible.
CALL {
MATCH (potential_user:GraphUser)
WHERE (potential_user.is_banned=false AND potential_user.is_paused=false AND potential_user.is_invisible=false AND potential_user.profile_complete=true)
RETURN potential_user }
MATCH (potential_user)
WITH potential_user, distance(point({srid:4326, x:-140.0312186, y:39.33233141}), potential_user.location) as distance
WHERE distance < 100000
RETURN count(potential_user);
This query performs slightly worse, ~200ms, and has a similar plan:
Yes, that's what I have in mind, but the way you have it set up isn't working the way I expect (but I don't know how to fix it!)
The first box with the big RED section returns 91K rows. The second box with the big red box searches 2.6M rows. It should (in theory) only search 91K rows but it's not.
I've modified it by commenting out the offending 2.6M MATCH, but I'm not sure if this works or not. Something like this:
CALL {
MATCH (potential_user:GraphUser)
WHERE (potential_user.is_banned=false AND potential_user.is_paused=false AND potential_user.is_invisible=false AND potential_user.profile_complete=true)
RETURN potential_user }
// MATCH (potential_user) // remove this big, bad match: matches 2.6M!!!!
WITH potential_user, distance(point({srid:4326, x:-140.0312186, y:39.33233141}), potential_user.location) as distance
WHERE distance < 100000
RETURN count(potential_user);
What's weird is that even if I just do a query on distance, it still has millions of db hits:
MATCH (potential_user:GraphUser)
WITH potential_user, distance(point({srid:4326, x:-140.0312186, y:39.33233141}), potential_user.location) as distance
WHERE distance < 100000
RETURN count(potential_user)
I have an index on GraphUser(location) but it doesn't seem to be using it.
It doesn't surprise me that indexing doesn't help with location because the query doesn't know how to limit the number of nodes searched based on the location because it has to go through a distance calculation. (In theory, some clever algo could handle this better).
Maybe try:
CALL {
MATCH (potential_user:GraphUser)
WHERE (potential_user.is_banned=false AND potential_user.is_paused=false AND potential_user.is_invisible=false AND potential_user.profile_complete=true)
RETURN potential_user AS pu // Try to get the 61k potential_users out of the subquery
}
WITH pu, distance(point({srid:4326, x:-140.0312186, y:39.33233141}), pu.location) AS distance
WHERE distance < 100000
RETURN count(pu);
I'm not clear on how to get the limited return results out of the subquery and pass it along to the second part of the query (filtering by distance.). You may have to fiddle with this some more.
I'm still at the intermediate level of Cypher and it sometimes surprises me!
MATCH (potential_user:GraphUser)
WHERE (potential_user.is_banned=false AND potential_user.is_paused=false AND potential_user.is_invisible=false AND potential_user.profile_complete=true)
WITH potential_user, distance(point({srid:4326, x:-140.0312186, y:39.33233141}), potential_user.location) as distance
WHERE distance < 100000
RETURN count(potential_user);
to
with point({srid:4326, x:-140.0312186, y:39.33233141}) as point1
MATCH (potential_user:GraphUser)
WHERE (potential_user.is_banned=false AND potential_user.is_paused=false AND potential_user.is_invisible=false AND potential_user.profile_complete=true)
WITH potential_user, distance(point1, potential_user.location) as distance
WHERE distance < 100000
RETURN count(potential_user);
any performance benefit? Also your query response times, is this after the 2nd run of the query. For example on a cold start of Neo4j the data to solve a query may first need to get the data from the file system , where as the 2nd run would get it from RAM, provided dbms.memory.pagecache.size is suffciently defined
PROFILE
CALL {
MATCH (potential_user:GraphUser)
WHERE (potential_user.is_banned=false AND potential_user.is_paused=false AND potential_user.is_invisible=false AND potential_user.profile_complete=true)
RETURN potential_user AS pu }
WITH pu, distance(point({srid:4326, x:-140.0312186, y:39.33233141}), pu.location) as distance
WHERE distance < 100000
RETURN count(pu);
WITH -140.0312186 AS Xcenter, 39.33233141 AS Ycenter,
pu,
0.5 AS Xslop, // where slop is some bounding box value is equivalent to +/-10000
0.5 AS Yslop // where slop is some bounding box value is equivalent to +/-10000
WHERE
pu.location.x < Xcenter) + Xslop AND
pu.location.x > Xcenter) - Xslop AND
pu.location.y < Ycenter) + Yslop AND
pu.location.y > Ycenter) - Yslop AND
distance(point({srid:4326, x:Xcenter, y:Ycenter}), pu.location) < maxdistance
The four pu.location tests are short circuit booleans, which will avoid the expensive (unindexed) distance calculations if the pu.location is outside the bounding box.
I'm not sure if Neo4j indexes the individual values of location.x and location.y, but you could create indexes for them. With this index, it will go faster.
The Xslop and Yslop may be trickier to calculate as they are in degrees and distance will vary by what location they are at.
can you execute -> db.prepareForReplanning() [caution if you are running in production] and rerun @dana_canzano query below ->
with point({srid:4326, x:-140.0312186, y:39.33233141}) as point1
MATCH (potential_user:GraphUser)
WHERE (potential_user.is_banned=false AND potential_user.is_paused=false AND potential_user.is_invisible=false AND potential_user.profile_complete=true)
WITH potential_user, distance(point1, potential_user.location) as distance
WHERE distance < 100000
RETURN count(potential_user);
again clear the cache, and try the below statement too
with point({srid:4326, x:-140.0312186, y:39.33233141}) as point1
MATCH (potential_user:GraphUser)
WHERE potential_user.is_banned=false AND potential_user.is_paused=false AND potential_user.is_invisible=false AND potential_user.profile_complete=true AND distance(potential_user.location,point1) < 100000
return count(potential_user);
one question for composite index -> potential_user.is_banned=false AND potential_user.is_paused=false AND potential_user.is_invisible=false AND potential_user.profile_complete=true is the order of the columns name in the query same as the order of composite index ordering.
Since, you are using composite index, i believe you are using enterprise version of neo4j. Can you let us know what is the build # ?
I'm guessing you did not create an index on the geolocation. (I didn't know you could do this until just now!). The bounding box search is done internally with an index, when there is an index.
(I haven't tried this myself, so I hope it will work for you.)
" If there is a index on a particular :Label(property) combination, and a spatial point is assigned to that property on a node with that label, the node will be indexed in a spatial index. For spatial indexing, Neo4j uses space filling curves in 2D or 3D over an underlying generalized B+Tree. "
this index helps in Polygon In-point queries.
As of as Neo4j 3.x,4.x, it supports only Point. there are other spatial like Linestring, Polygon etc
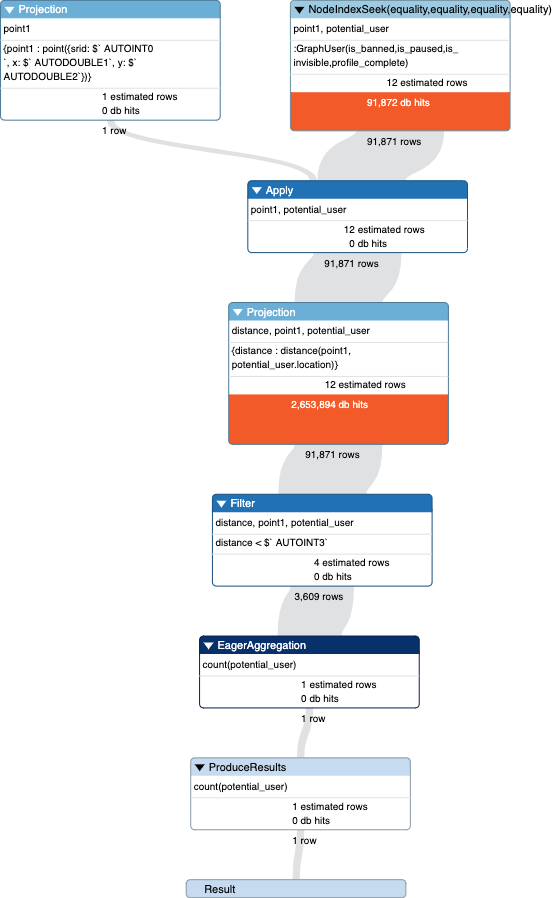
Thanks for the suggestions. Both queries have about the same performance after running the prepareForReplanning() function. They are running around 200ms. Here is the query plan:
The only way I can get the db hits lower, is to use @clem 's suggestion of forcing the results of the index scan into a different variable. This reduces the average execution time to around 70ms.
I should point out that this really is just the beginning of a much larger query with a lot more conditions, and likely there will be a UNION with another query that deals with relationships. (The current query that is in production on a relational db has four joins). So it's a little disconcerting that this simple spatial query is performing so slowly, and it's also awkward that just adding a few more conditions to this adds tons of db hits and degrades performance.
Granted, I am very new to cypher and maybe I really need to understand the query chaining and indexing (I clearly don't), but are my expectations just not set appropriately?
FWIW, I'm running this on Desktop MacOS version 4.0.8.